
Мета-тег robots используют, чтобы дать поисковым роботам инструкции для конкретной страницы: показывать ее в результатах поиска или нет, обрабатывать ссылки на ней или нет, формировать сниппет, показывать превью изображений или убирать страницу после определенной даты.
Это не замена robots.txt. Файл robots.txt управляет сканированием URL, а meta robots работает на уровне отдельной HTML-страницы после того, как робот смог ее открыть. Если страницу нужно убрать из индекса Google, используйте noindex и не блокируйте эту страницу в robots.txt, иначе Googlebot может не увидеть запрет индексации.
В SEO-Evolution мы проверяем meta robots во время технического аудита вместе с robots.txt, canonical, sitemap.xml, страницами фильтров, пагинацией, языковыми версиями и статусами в Google Search Console. Если на сайте есть случайный noindex, закрытые важные разделы или конфликтующие правила, трафик может проседать даже тогда, когда контент и ссылки выглядят нормально.
Ниже — актуальная логика работы meta robots, noindex, nofollow, X-Robots-Tag и типичных ошибок, из-за которых страницы не индексируются или остаются в Google дольше, чем ожидалось.
Что такое meta robots
Meta robots или мета-тег robots — это HTML-тег, который размещается в коде страницы и передает поисковым системам правила ее обработки. Чаще всего он находится в секции <head> .
<meta name="robots" content="noindex">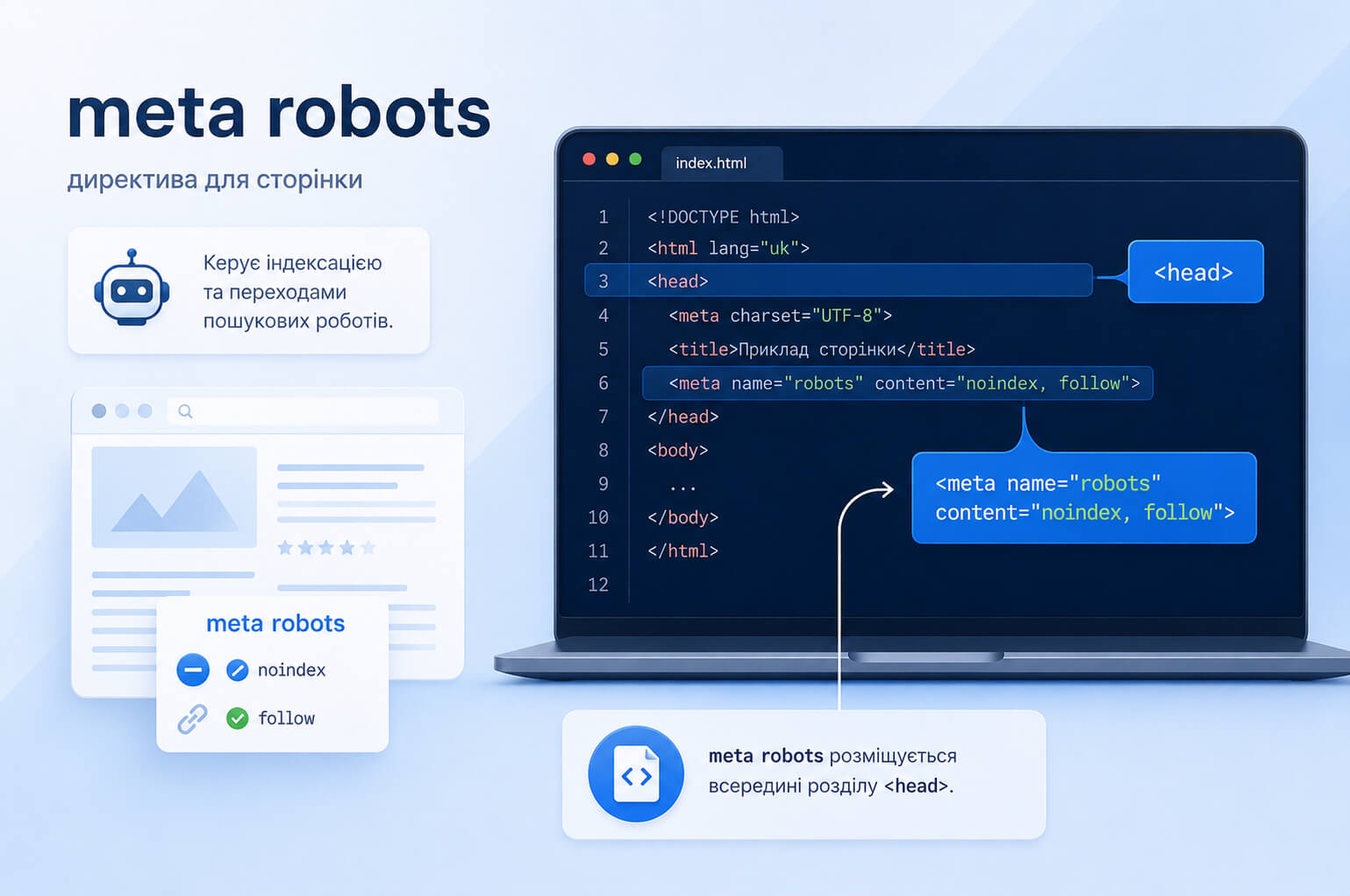
В записи meta name="robots" content="noindex" атрибут name показывает, для каких роботов действует правило, а content содержит саму директиву. Если указано robots , правило адресовано всем поисковым роботам, которые поддерживают соответствующую директиву.
Для Google можно задать отдельное правило через googlebot :
<meta name="googlebot" content="noindex">В большинстве случаев достаточно общего варианта name="robots" . Отдельные правила для Googlebot используйте только тогда, когда есть конкретная техническая задача.
Документация Google описывает robots meta tag как постраничный способ управлять индексацией и показом контента в результатах поиска. Проверить актуальные директивы можно в официальной документации Google о robots meta tag и X-Robots-Tag .
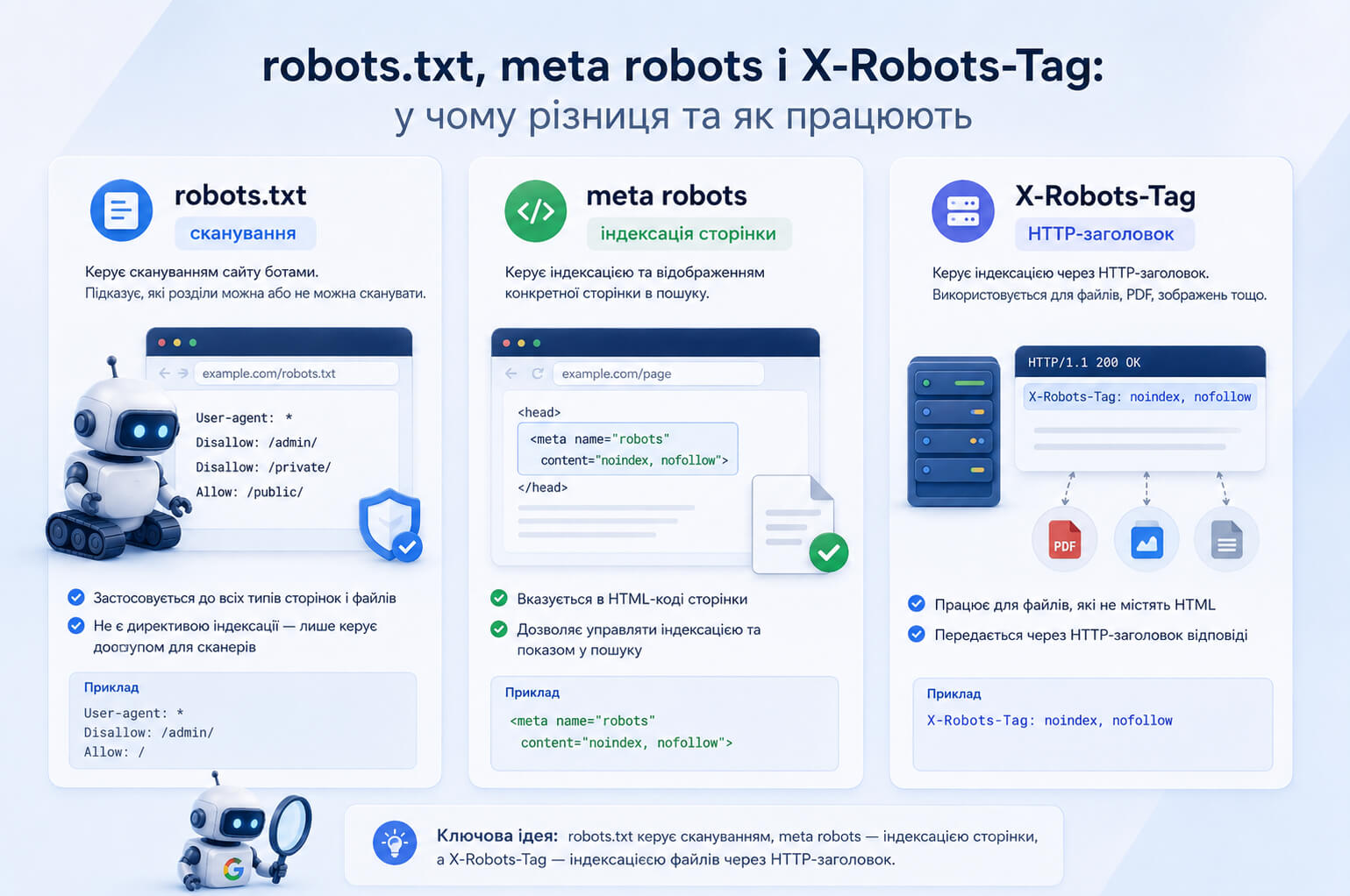
Meta robots и robots.txt — в чем разница
Meta robots и robots.txt часто используют рядом, но они отвечают за разные вещи. Robots.txt нужен для управления сканированием, meta robots — для управления индексацией и показом конкретной страницы в поиске.
| Инструмент | Что регулирует | Когда использовать |
| robots.txt | Сканирование URL поисковыми роботами | Когда нужно ограничить обход технических или неважных для сканирования разделов |
| meta robots | Индексацию и показ HTML-страницы в поиске | Когда страница должна быть доступна пользователю, но не должна появляться в Google |
| X-Robots-Tag | Индексацию через HTTP-заголовок | Когда нужно управлять индексацией PDF, изображений, видео или группы URL на уровне сервера |
Пример robots.txt:
User-agent: *
Disallow: /private/Это правило запрещает роботам сканировать раздел /private/ . Но оно не гарантирует, что URL не появится в поиске, если Google найдет его через внутренние или внешние ссылки.
Если HTML-страницу нужно убрать из Google, добавьте noindex и оставьте ее доступной для сканирования:
<meta name="robots" content="noindex">Запись Noindex в robots.txt не используйте. Google не поддерживает такой способ запрета индексации:
User-agent: *
Noindex: /example-page/Подробнее о самом файле можно прочитать в статье что такое robots.txt и зачем он нужен . В этой статье фокус именно на meta robots, noindex, nofollow и X-Robots-Tag.
Где размещается meta robots в HTML
Meta robots добавляют в секцию <head> нужной страницы:
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<title>Название страницы</title>
<meta name="robots" content="noindex, follow">
</head>
<body>
...
</body>
</html>На сайтах с CMS это правило часто добавляют через SEO-модуль, шаблон страницы, настройки типа контента или глобальные настройки темы. После редизайна, переноса сайта или запуска нового шаблона проверьте разные типы URL: главную, услуги, категории, товары, статьи блога, фильтры, пагинацию, языковые версии и служебные страницы.
В рамках технического аудита сайта такие проверки помогают найти случайный noindex, закрытые страницы в robots.txt, неправильные canonical и конфликты между шаблонами CMS и серверными заголовками.
Noindex, nofollow, index и follow – как использовать
В meta robots есть две базовые группы правил. Первая управляет индексацией самой страницы. Вторая — обработкой ссылок на этой странице.
| Директива | Что регулирует | Простое объяснение |
| index | Индексацию страницы | Страницу можно добавлять в индекс и показывать в поиске. Это поведение по умолчанию. |
| noindex | Индексацию страницы | Страницу не нужно показывать в результатах поиска. |
| follow | Ссылки на странице | Робот может использовать ссылки на странице для обнаружения связанных URL. Это тоже поведение по умолчанию. |
| nofollow | Ссылки на странице | Робот не должен переходить по ссылкам, размещенным на этой странице. |
| none | Страницу и ссылки | Сокращение для noindex, nofollow . |
| all | Страницу и ссылки | Дефолтное поведение без ограничений. Для Google явное добавление этой директивы не дает дополнительного эффекта. |

Главное разделение такое: noindex касается индексации страницы, nofollow — ссылок на странице. Если в meta robots указано только nofollow, это не означает, что страница закрыта от индексации.
Основные комбинации meta robots
В content можно комбинировать несколько правил через запятую. Ниже — комбинации, которые чаще всего встречаются в SEO.
| Запись | Что означает | Комментарий |
<meta name="robots" content="index, follow"> |
Индексировать страницу и переходить по ссылкам | Обычно не нужно прописывать, потому что это стандартное поведение. |
<meta name="robots" content="noindex, follow"> |
Не показывать страницу в поиске, но разрешить обработку ссылок | Подходит для части служебных или дублирующих страниц, если ссылки на них помогают роботу двигаться дальше. |
<meta name="robots" content="noindex, nofollow"> |
Не индексировать страницу и не переходить по ссылкам | Строгое правило. Перед использованием проверьте, не обрывает ли оно важную внутреннюю навигацию. |
<meta name="robots" content="none"> |
То же самое, что noindex, nofollow |
Короткая запись. Для прозрачности в больших командах часто удобнее писать полную комбинацию. |
<meta name="robots" content="all"> |
Без ограничений | Для Google это дефолтное правило, поэтому его редко нужно добавлять явно. |
Если на странице одновременно появляются противоречивые правила, Google ориентируется на более ограничивающее. Поэтому при проверке смотрите не только HTML-код, но и HTTP-заголовки, шаблоны CMS, SEO-плагины и правила на сервере.
Когда использовать noindex
Noindex нужен тогда, когда страница должна оставаться доступной для пользователя, но не должна появляться в результатах поиска. Это может быть страница благодарности после заявки, внутренний поиск по сайту, часть технических фильтров, временная страница на рабочем домене или дублирующая страница без самостоятельной поисковой ценности.
<meta name="robots" content="noindex">Перед тем как закрыть страницу от индексации, проверьте данные в Google Search Console: показы, клики, запросы, внутренние ссылки и каноническую версию. Страница может казаться слабой, но иметь полезный длинный хвост запросов или помогать пользователю перейти к конверсии.
Не используйте noindex как универсальный способ убрать все слабые страницы. Сначала определите причину: отсутствие спроса, дублирование, тонкий контент, неправильный canonical, лишние фильтры, плохая структура или несоответствие намерению пользователя.
Nofollow в meta robots и rel="nofollow" — разные вещи
Meta robots nofollow работает на уровне всей страницы:
<meta name="robots" content="nofollow">Это правило касается всех ссылок, которые размещены на странице. Оно не запрещает индексацию самой страницы. Если на странице стоит только nofollow, Google может индексировать страницу, но не должен переходить по ссылкам с нее.
| Вариант | Как работает |
<meta name="robots" content="nofollow"> |
Применяется ко всем ссылкам на странице. |
<a href="..." rel="nofollow"> |
Применяется к одной конкретной ссылке. |
Если нужно отметить рекламную, партнерскую или пользовательскую ссылку, работайте с атрибутами конкретного линка: rel="nofollow" , rel="sponsored" или rel="ugc" . Meta robots nofollow не подходит для выборочного управления одной ссылкой.
Canonical, 404, 410 и noindex: что выбрать
Noindex не заменяет canonical, 404, 410 или 301-редирект. Это разные инструменты для разных ситуаций.
| Ситуация | Что использовать | Пояснение |
| Есть несколько похожих URL, но один основной | Canonical | Показывает желательную каноническую страницу, но не гарантирует удаление дубля из индекса. |
| Страница доступна пользователю, но не нужна в поиске | Noindex | Страница может открываться, но не должна показываться в Google. |
| Контент удален и замены нет | 404 или 410 | Поисковая система получает сигнал, что страницы больше не существует. |
| Есть новая релевантная страница вместо старой | 301-редирект | Пользователь и робот переходят на актуальный URL. |

Например, если товар полностью снят с продажи и не имеет аналога, чаще логичен 404 или 410. Если товар заменен новой моделью, уместен 301-редирект. Если страница нужна пользователю, но не должна попадать в Google, используйте noindex.
Когда нужен X-Robots-Tag
X-Robots-Tag — это HTTP-заголовок, который задается в ответе сервера. Он выполняет похожую задачу с meta robots, но работает не в HTML-коде, а на уровне HTTP-ответа.
HTTP/1.1 200 OK
X-Robots-Tag: noindexX-Robots-Tag нужен, когда вы не можете добавить meta robots в HTML или работаете с файлами не-HTML формата: PDF, изображениями, видео, документами для загрузки.
Для PDF-файлов правило может выглядеть так:
X-Robots-Tag: noindexПример для Apache:
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>Пример для NGINX:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}Перед массовым noindex для файлов проверьте, не приносят ли они трафик. Инструкции, публичные каталоги, технические документы, презентации или прайс-листы иногда имеют собственную поисковую ценность.
Директивы Google для сниппетов, изображений и временных страниц
Кроме noindex и nofollow, Google поддерживает дополнительные правила для управления видом страницы в результатах поиска.
| Директива | Что делает |
| nosnippet | Запрещает показ текстового сниппета и видеопревью для страницы. |
| max-snippet | Ограничивает максимальное количество символов в текстовом сниппете. |
| max-image-preview | Управляет размером превью изображения в поиске. |
| max-video-preview | Ограничивает длительность видеопревью. |
| notranslate | Запрещает предлагать перевод страницы в результатах поиска. |
| noimageindex | Запрещает индексацию изображений на странице. |
| unavailable_after | Указывает дату, после которой страницу не нужно показывать в поиске. |

Пример для сниппета и превью изображения:
<meta name="robots" content="max-snippet:160, max-image-preview:large">Пример для страницы, которую нужно убрать из поиска после определенной даты:
<meta name="robots" content="unavailable_after: Wed, 31 Dec 2026 23:59:59 GMT">Для unavailable_after используйте дату в формате, который Google может распознать. Если формат невалидный, директива может быть проигнорирована.
Не ограничивайте сниппет или изображения без причины. Для страниц, которые уже хорошо работают в поиске, такие директивы могут ухудшить вид результата и снизить кликабельность.
Устаревшие директивы в старых шаблонах
В старых SEO-инструкциях и шаблонах до сих пор встречаются директивы, которые уже не имеют практического смысла для Google или связаны с давно неактуальными механизмами поиска.
| Директива | Что с ней сейчас |
| noarchive | Google больше не использует кешированную ссылку в том виде, для которого эта директива была нужна. |
| nocache | Не используется Google Search. |
| nositelinkssearchbox | Не используется Google Search для управления sitelinks search box. |
| noodp | Устаревшая директива со времен каталогов, которые уже не влияют на формирование сниппетов в Google. |
| noydir | Устаревшая директива, связанная со старыми механизмами поисковых систем. |
Если в шаблоне сайта до сих пор есть noodp , noydir или другие исторические правила, это не всегда критическая ошибка. Но это хороший повод полностью пересмотреть технические настройки индексации.
Типичные ошибки с meta robots
Проблемы с meta robots обычно возникают не из-за самого тега, а из-за неправильной логики внедрения. Ниже — ошибки, которые чаще всего влияют на индексацию.

Noindex и запрет в robots.txt одновременно
Если страницу закрыли в robots.txt, Googlebot может не открыть ее и не увидеть noindex. Для удаления страницы из поиска разрешите сканирование и добавьте noindex.
Случайный noindex в шаблоне
После разработки или редизайна noindex иногда остается на всех страницах, отдельном типе страниц или языковой версии. Проверьте типовые URL: услуги, категории, товары, статьи, пагинацию, фильтры, страницы городов.
Лишний index, follow
Запись index, follow обычно не вредит, но и не решает задачу. Если страница должна индексироваться, достаточно не ставить ограничивающих директив.
Meta robots nofollow вместо rel="nofollow"
Если нужно отметить одну рекламную или партнерскую ссылку, не закрывайте все ссылки на странице через meta robots nofollow. Используйте атрибут для конкретной ссылки.
Noindex на страницах с трафиком
Перед закрытием страницы проверьте, приносит ли она показы, клики или конверсии. Для страниц с потенциалом иногда лучше обновить контент, изменить структуру, доработать перелинковку или объединить дубли через canonical.
Noindex отсутствует на тестовой копии сайта
Тестовая копия сайта не должна попадать в индекс. Мы часто видим эту ошибку при анализе сайтов, которые обращаются в SEO-Evolution после просадки трафика: dev-домен, поддомен или техническая копия открыты для сканирования, страницы имеют стандартное поведение index, follow и постепенно появляются в Google.
Это создает дубли рабочего сайта, путает поисковые системы и может влиять на индексацию основных страниц. Тестовую версию лучше закрывать не только через noindex, но и через парольный доступ или ограничение по IP. Noindex подходит как дополнительный уровень, но не как единственный способ защиты технической копии.
Noindex всего сайта в WordPress после запуска
Обратная ситуация тоже встречается часто: сайт уже перенесли на рабочий домен, но в WordPress остался включенным запрет индексации. В таком случае страницы могут иметь meta robots noindex, nofollow, хотя сайт уже должен индексироваться и получать трафик из поиска.
Проверьте это в админпанели WordPress: Настройки → Чтение → Видимость для поисковых систем . Если стоит галочка возле пункта Попросить поисковые системы не индексировать этот сайт , ее нужно снять и нажать Сохранить изменения . В англоязычной админпанели путь выглядит так: Settings → Reading → Search Engine Visibility → Discourage search engines from indexing this site.
После этого проверьте несколько важных страниц в Google Search Console через URL Inspection Tool. Если Google уже видел noindex, ему нужно время на повторное сканирование и обновление статуса страниц.
Как проверить noindex и meta robots в Google Search Console
Проверку нужно делать на нескольких уровнях. Один просмотр HTML-кода не всегда показывает всю картину, потому что правило может приходить через HTTP-заголовок или меняться после рендеринга.
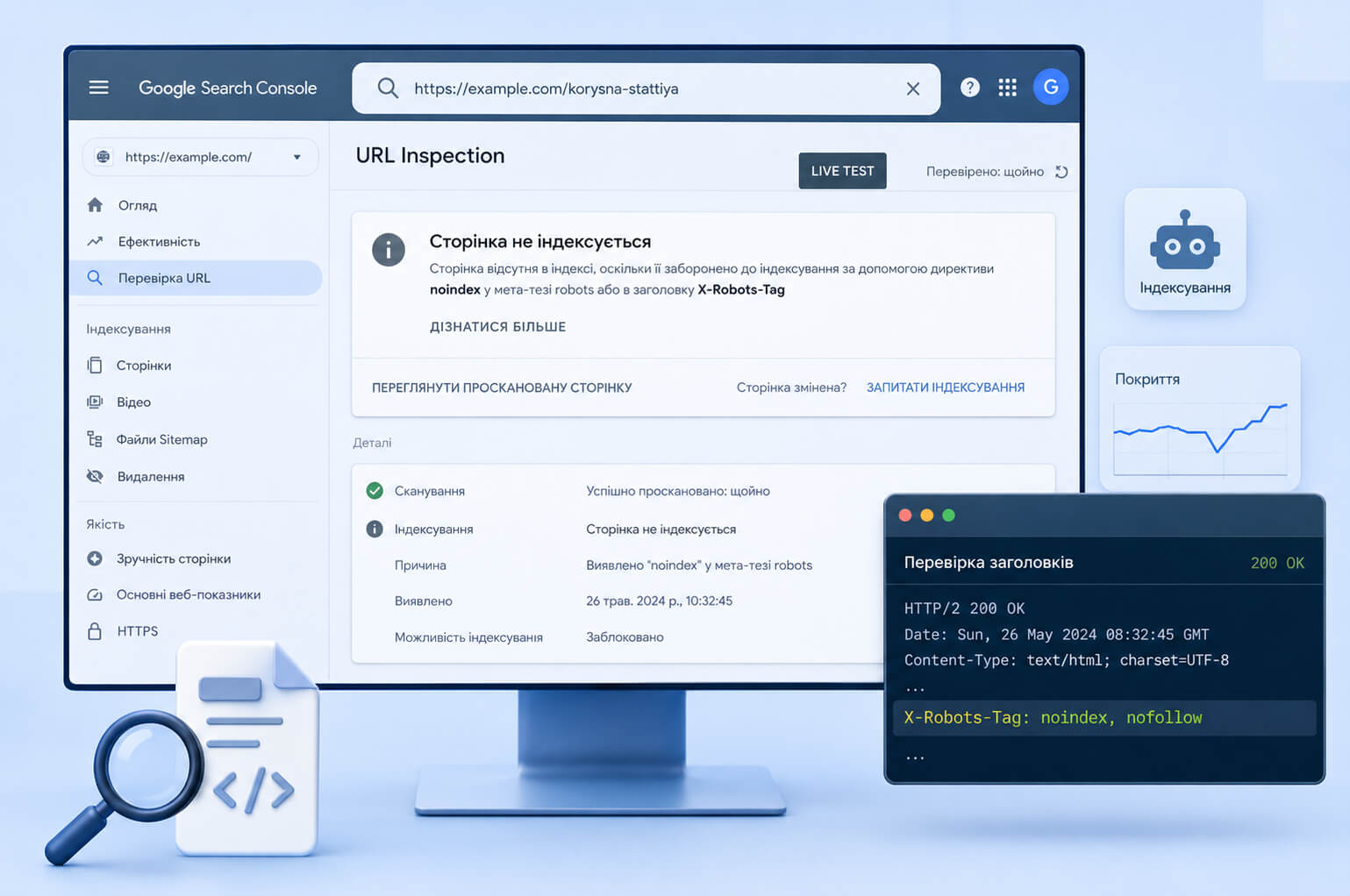
- Откройте страницу в браузере, просмотрите исходный код и найдите
meta name="robots". - Проверьте URL в Google Search Console через URL Inspection Tool.
- Запустите live test, чтобы увидеть актуальную версию страницы для Googlebot.
- Посмотрите Page Indexing report и найдите страницы со статусами, связанными с noindex.
- Проверьте HTTP-заголовки, если подозреваете X-Robots-Tag.
- Сравните meta robots, robots.txt, canonical и sitemap.
Для быстрой проверки HTTP-заголовков можно использовать команду:
curl -I https://example.com/file.pdfЕсли в ответе есть X-Robots-Tag: noindex , индексацией управляет серверный заголовок, а не HTML-код страницы.
В Google Search Console проблема может отображаться как страница, где индексирование запрещено тегом noindex. Если noindex уже убрали, запросите повторное сканирование через URL Inspection Tool и дождитесь обновления статуса. Для большого количества URL обновите sitemap и проверьте, не блокирует ли страницы robots.txt.
Вывод
Мета-тег robots нужен для управления тем, как поисковые системы обрабатывают конкретную HTML-страницу. Noindex отвечает за индексацию страницы, nofollow — за ссылки на странице. Это разные действия, поэтому их нужно настраивать отдельно и не смешивать с атрибутами отдельных ссылок.
Robots.txt не заменяет meta robots. Он ограничивает сканирование, но не является надежным способом убрать HTML-страницу из Google. Для запрета показа страницы в поиске используйте noindex, для PDF и других не-HTML файлов — X-Robots-Tag, для удаленных страниц — 404, 410 или 301-редирект в зависимости от ситуации.
Перед изменениями проверьте, какие страницы уже приносят трафик, где есть дубли, какие URL нужны пользователям, а какие создают технический шум. Если noindex, canonical, robots.txt и sitemap настроены хаотично, SEO-продвижение сайта нужно начинать с технической очистки индексации. Примеры комплексной работы над сайтами можно посмотреть в портфолио SEO-Evolution .










