
Мета-тег robots використовують, щоб дати пошуковим роботам інструкції для конкретної сторінки: показувати її в результатах пошуку чи ні, обробляти посилання на ній чи ні, формувати сніпет, показувати прев’ю зображень або прибирати сторінку після певної дати.
Це не заміна robots.txt. Файл robots.txt керує скануванням URL, а meta robots працює на рівні окремої HTML-сторінки після того, як робот зміг її відкрити. Якщо сторінку потрібно прибрати з індексу Google, використовуйте noindex і не блокуйте цю сторінку в robots.txt, інакше Googlebot може не побачити заборону індексації.
У SEO-Evolution ми перевіряємо meta robots під час технічного аудиту разом із robots.txt, canonical, sitemap.xml, сторінками фільтрів, пагінацією, мовними версіями та статусами в Google Search Console. Якщо на сайті є випадковий noindex, закриті важливі розділи або конфліктні правила, трафік може просідати навіть тоді, коли контент і посилання виглядають нормальними.
Нижче — актуальна логіка роботи meta robots, noindex, nofollow, X-Robots-Tag і типових помилок, через які сторінки не індексуються або залишаються в Google довше, ніж очікувалося.
Що таке meta robots
Meta robots або мета-тег robots — це HTML-тег, який розміщується в коді сторінки й передає пошуковим системам правила її обробки. Найчастіше він стоїть у секції <head> .
<meta name="robots" content="noindex">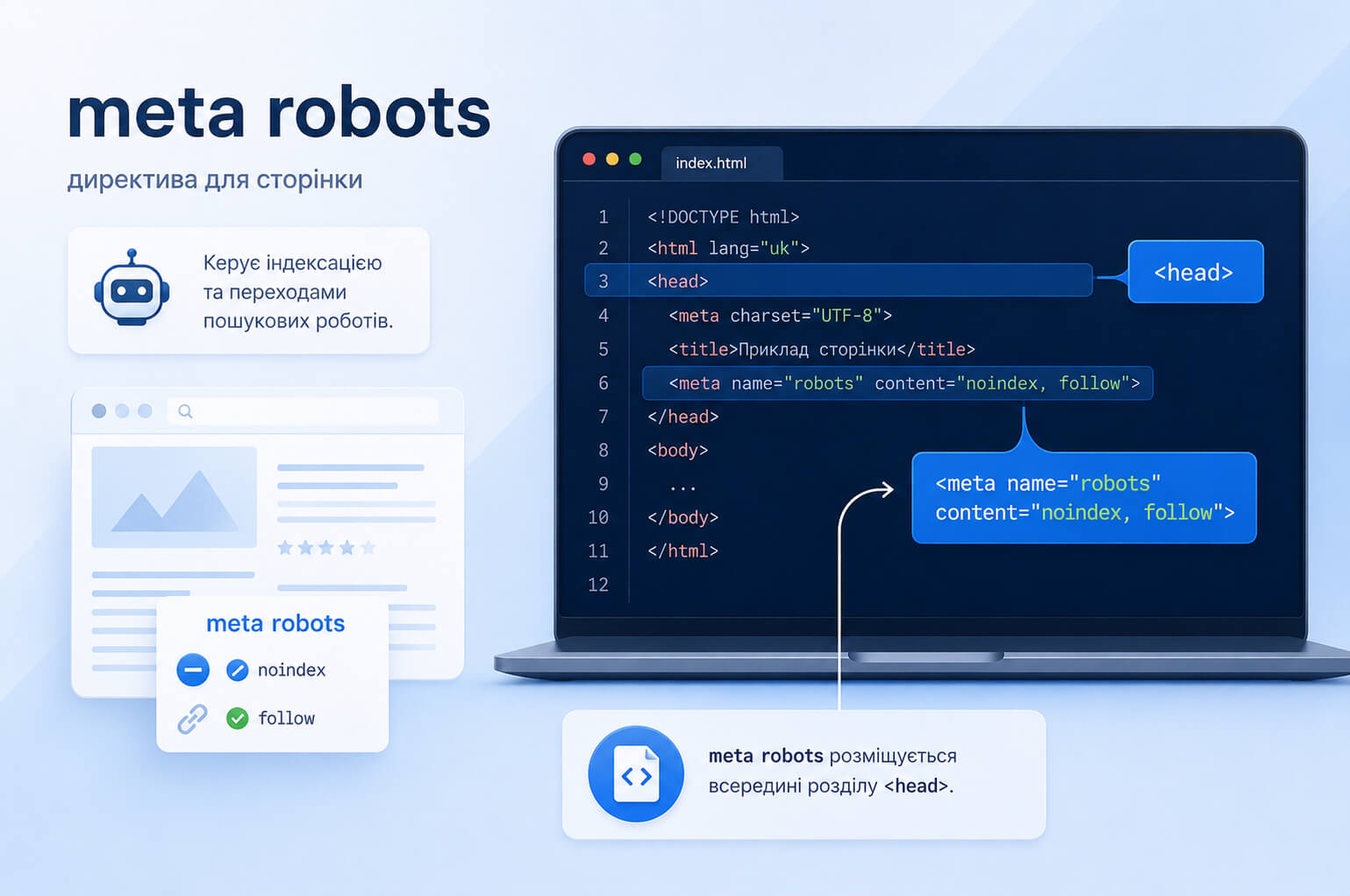
У записі meta name="robots" content="noindex" атрибут name показує, для яких роботів діє правило, а content містить саму директиву. Якщо вказано robots , правило адресоване всім пошуковим роботам, які підтримують відповідну директиву.
Для Google можна задати окреме правило через googlebot :
<meta name="googlebot" content="noindex">У більшості випадків достатньо загального варіанта name="robots" . Окремі правила для Googlebot використовуйте лише тоді, коли є конкретна технічна задача.
Документація Google описує robots meta tag як сторінковий спосіб керувати індексацією і показом контенту в результатах пошуку. Перевірити актуальні директиви можна в офіційній документації Google про robots meta tag і X-Robots-Tag .
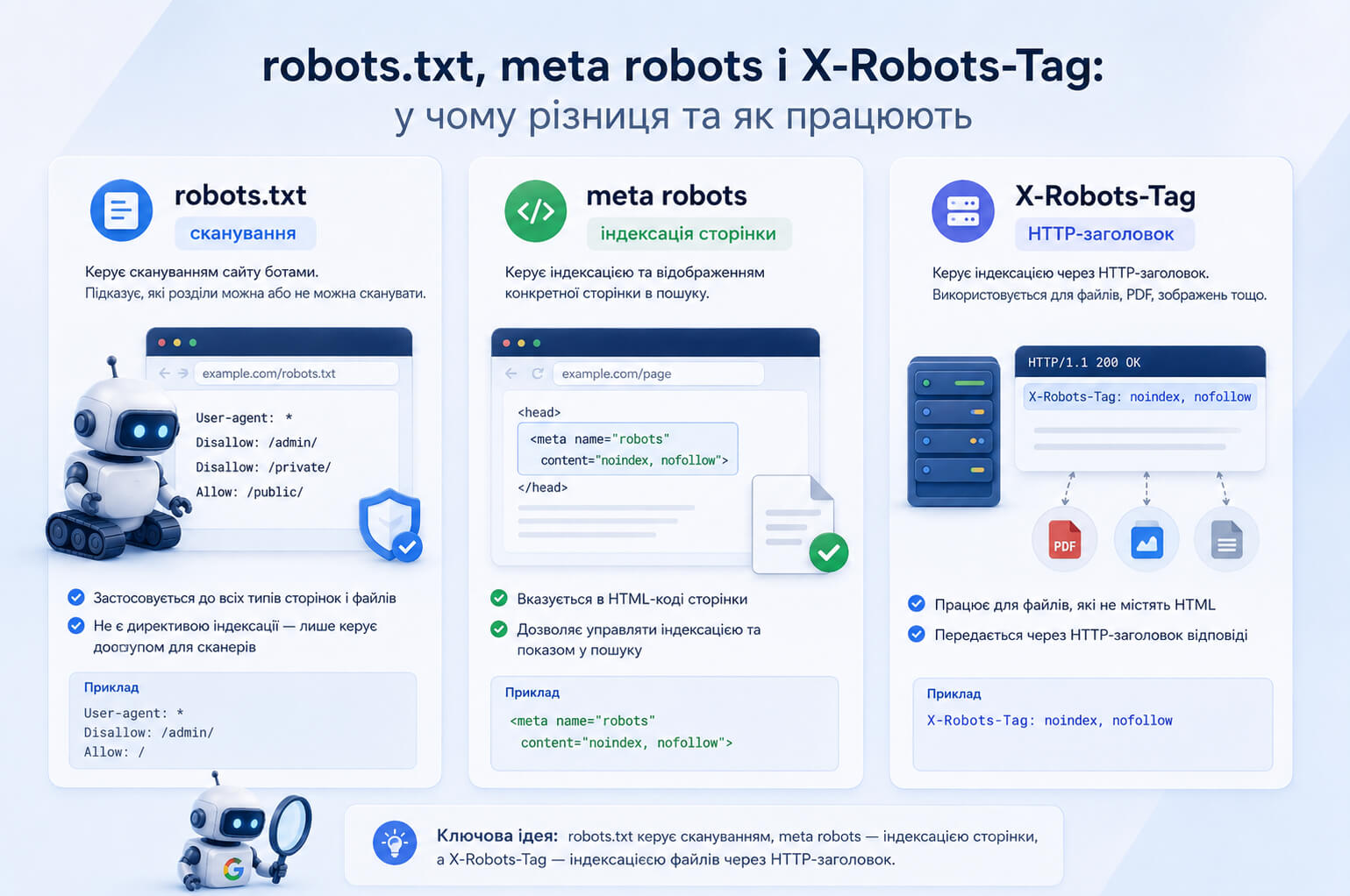
Meta robots і robots.txt — у чому різниця
Meta robots і robots.txt часто використовують поруч, але вони відповідають за різні речі. Robots.txt потрібен для керування скануванням, meta robots — для керування індексацією і показом конкретної сторінки в пошуку.
| Інструмент | Що регулює | Коли використовувати |
| robots.txt | Сканування URL пошуковими роботами | Коли потрібно обмежити обхід технічних або неважливих для сканування розділів |
| meta robots | Індексацію і показ HTML-сторінки в пошуку | Коли сторінка має бути доступною для користувача, але не повинна з’являтися в Google |
| X-Robots-Tag | Індексацію через HTTP-заголовок | Коли потрібно керувати індексацією PDF, зображень, відео або групи URL на рівні сервера |
Приклад robots.txt:
User-agent: *
Disallow: /private/Це правило забороняє роботам сканувати розділ /private/ . Але воно не гарантує, що URL не з’явиться в пошуку, якщо Google знайде його через внутрішні або зовнішні посилання.
Якщо HTML-сторінку потрібно прибрати з Google, додайте noindex і залиште її доступною для сканування:
<meta name="robots" content="noindex">Запис Noindex у robots.txt не використовуйте. Google не підтримує такий спосіб заборони індексації:
User-agent: *
Noindex: /example-page/Детальніше про сам файл можна прочитати в статті що таке robots.txt і навіщо він потрібен . У цій статті фокус саме на meta robots, noindex, nofollow і X-Robots-Tag.
Де розміщується meta robots у HTML
Meta robots додають у секцію <head> потрібної сторінки:
<!DOCTYPE html>
<html lang="uk">
<head>
<meta charset="UTF-8">
<title>Назва сторінки</title>
<meta name="robots" content="noindex, follow">
</head>
<body>
...
</body>
</html>На сайтах із CMS це правило часто додають через SEO-модуль, шаблон сторінки, налаштування типу контенту або глобальні налаштування теми. Після редизайну, перенесення сайту або запуску нового шаблону перевірте різні типи URL: головну, послуги, категорії, товари, статті блогу, фільтри, пагінацію, мовні версії та службові сторінки.
У межах технічного аудиту сайту такі перевірки допомагають знайти випадковий noindex, закриті сторінки в robots.txt, неправильні canonical і конфлікти між шаблонами CMS та серверними заголовками.
Noindex, nofollow, index і follow – як використовувати
У meta robots є дві базові групи правил. Перша керує індексацією самої сторінки. Друга — обробкою посилань на цій сторінці.
| Директива | Що регулює | Просте пояснення |
| index | Індексацію сторінки | Сторінку можна додавати в індекс і показувати в пошуку. Це поведінка за замовчуванням. |
| noindex | Індексацію сторінки | Сторінку не потрібно показувати в результатах пошуку. |
| follow | Посилання на сторінці | Робот може використовувати посилання на сторінці для виявлення пов’язаних URL. Це також поведінка за замовчуванням. |
| nofollow | Посилання на сторінці | Робот не має переходити за посиланнями, які розміщені на цій сторінці. |
| none | Сторінку і посилання | Скорочення для noindex, nofollow . |
| all | Сторінку і посилання | Дефолтна поведінка без обмежень. Для Google явне додавання цієї директиви не дає додаткового ефекту. |

Головне розділення таке: noindex стосується індексації сторінки, nofollow — посилань на сторінці. Якщо у meta robots вказано тільки nofollow, це не означає, що сторінка закрита від індексації.
Основні комбінації meta robots
У "content" можна комбінувати кілька правил через кому. Нижче — комбінації, які найчастіше зустрічаються в SEO.
| Запис | Що означає | Коментар |
<meta name="robots" content="index, follow"> |
Індексувати сторінку і переходити за посиланнями | Зазвичай не потрібно прописувати, бо це стандартна поведінка. |
<meta name="robots" content="noindex, follow"> |
Не показувати сторінку в пошуку, але дозволити обробку посилань | Підходить для частини службових або дубльованих сторінок, якщо посилання на них допомагають роботу рухатися далі. |
<meta name="robots" content="noindex, nofollow"> |
Не індексувати сторінку і не переходити за посиланнями | Суворе правило. Перед використанням перевірте, чи не обриває воно важливу внутрішню навігацію. |
<meta name="robots" content="none"> |
Те саме, що noindex, nofollow |
Короткий запис. Для прозорості у великих командах часто зручніше писати повну комбінацію. |
<meta name="robots" content="all"> |
Без обмежень | Для Google це дефолтне правило, тому його рідко потрібно додавати явно. |
Якщо на сторінці одночасно з’являються суперечливі правила, Google орієнтується на більш обмежувальне. Тому під час перевірки дивіться не тільки HTML-код, а й HTTP-заголовки, шаблони CMS, SEO-плагіни та правила на сервері.
Коли використовувати noindex
Noindex потрібен тоді, коли сторінка має залишатися доступною для користувача, але не повинна з’являтися в результатах пошуку. Це може бути сторінка подяки після заявки, внутрішній пошук по сайту, частина технічних фільтрів, тимчасова сторінка на робочому домені або дубльована сторінка без самостійної пошукової цінності.
<meta name="robots" content="noindex">Перед тим як закрити сторінку від індексації, перевірте дані в Google Search Console: покази, кліки, запити, внутрішні посилання і канонічну версію. Сторінка може здаватися слабкою, але мати корисний довгий хвіст запитів або допомагати користувачу перейти до конверсії.
Не використовуйте noindex як універсальний спосіб прибрати всі слабкі сторінки. Спершу визначте причину: відсутність попиту, дублювання, тонкий контент, неправильний canonical, зайві фільтри, погана структура або невідповідність наміру користувача.
Nofollow у meta robots і rel="nofollow" — різні речі
Meta robots nofollow працює на рівні всієї сторінки:
<meta name="robots" content="nofollow">Це правило стосується всіх посилань, які розміщені на сторінці. Воно не забороняє індексацію самої сторінки. Якщо на сторінці стоїть тільки nofollow, Google може індексувати сторінку, але не має переходити за посиланнями з неї.
| Варіант | Як працює |
<meta name="robots" content="nofollow"> |
Застосовується до всіх посилань на сторінці. |
<a href="..." rel="nofollow"> |
Застосовується до одного конкретного посилання. |
Якщо потрібно закрити якесь окреме, позначити рекламне, партнерське або користувацьке посилання, працюйте з атрибутами конкретного лінка: rel="nofollow" , rel="sponsored" або rel="ugc" . Meta robots nofollow не підходить для вибіркового керування одним посиланням.
Canonical, 404, 410 і noindex: що вибрати
Noindex не замінює canonical, 404, 410 або 301-редирект. Це різні інструменти для різних ситуацій.
| Ситуація | Що використовувати | Пояснення |
| Є кілька схожих URL, але один основний | Canonical | Показує бажану канонічну сторінку, але не гарантує вилучення дубля з індексу. |
| Сторінка доступна користувачу, але не потрібна в пошуку | Noindex | Сторінка може відкриватися, але не має показуватися в Google. |
| Контент видалено і заміни немає | 404 або 410 | Пошукова система отримує сигнал, що сторінки більше не існує. |
| Є нова релевантна сторінка замість старої | 301-редирект | Користувач і робот переходять на актуальний URL. |

Наприклад, якщо товар повністю знятий із продажу і не має аналога, частіше логічний 404 або 410. Якщо товар замінений новою моделлю, доречний 301-редирект. Якщо сторінка потрібна користувачу, але не має потрапляти в Google, використовуйте noindex.
Коли потрібен X-Robots-Tag
X-Robots-Tag — це HTTP-заголовок, який задається у відповіді сервера. Він виконує схожу задачу з meta robots, але працює не в HTML-коді, а на рівні HTTP-відповіді.
HTTP/1.1 200 OK
X-Robots-Tag: noindexX-Robots-Tag потрібен, коли ви не можете додати meta robots у HTML або працюєте з файлами не-HTML формату: PDF, зображеннями, відео, документами для завантаження.
Для PDF-файлів правило може виглядати так:
X-Robots-Tag: noindexПриклад для Apache:
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>Приклад для NGINX:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}Перед масовим noindex для файлів перевірте, чи не приносять вони трафік. Інструкції, публічні каталоги, технічні документи, презентації або прайс-листи іноді мають власну пошукову цінність.
Директиви Google для сніпетів, зображень і тимчасових сторінок
Крім noindex і nofollow, Google підтримує додаткові правила для керування виглядом сторінки в результатах пошуку.
| Директива | Що робить |
| nosnippet | Забороняє показ текстового сніпета і відеопрев’ю для сторінки. |
| max-snippet | Обмежує максимальну кількість символів у текстовому сніпеті. |
| max-image-preview | Керує розміром прев’ю зображення в пошуку. |
| max-video-preview | Обмежує тривалість відеопрев’ю. |
| notranslate | Забороняє пропонувати переклад сторінки в результатах пошуку. |
| noimageindex | Забороняє індексацію зображень на сторінці. |
| unavailable_after | Вказує дату, після якої сторінку не потрібно показувати в пошуку. |

Приклад для сніпета і прев’ю зображення:
<meta name="robots" content="max-snippet:160, max-image-preview:large">Приклад для сторінки, яку потрібно прибрати з пошуку після певної дати:
<meta name="robots" content="unavailable_after: Wed, 31 Dec 2026 23:59:59 GMT">Для unavailable_after використовуйте дату у форматі, який Google може розпізнати. Якщо формат невалідний, директива може бути проігнорована.
Не обмежуйте сніпет або зображення без причини. Для сторінок, які вже добре працюють у пошуку, такі директиви можуть погіршити вигляд результату й знизити клікабельність.
Застарілі директиви в старих шаблонах
У старих SEO-інструкціях і шаблонах досі трапляються директиви, які вже не мають практичного сенсу для Google або пов’язані з давно неактуальними механізмами пошуку.
| Директива | Що з нею зараз |
| noarchive | Google більше не використовує кешоване посилання в тому вигляді, для якого ця директива була потрібна. |
| nocache | Не використовується Google Search. |
| nositelinkssearchbox | Не використовується Google Search для керування sitelinks search box. |
| noodp | Застаріла директива з часів каталогів, які вже не впливають на формування сніпетів у Google. |
| noydir | Застаріла директива, пов’язана зі старими механізмами пошукових систем. |
Якщо у шаблоні сайту досі є noodp , noydir або інші історичні правила, це не завжди критична помилка. Але це добрий привід переглянути технічні налаштування індексації повністю.
Типові помилки з meta robots
Проблеми з meta robots зазвичай виникають не через сам тег, а через неправильну логіку впровадження. Нижче — помилки, які найчастіше впливають на індексацію.

Noindex і заборона в robots.txt одночасно
Якщо сторінку закрили в robots.txt, Googlebot може не відкрити її й не побачити noindex. Для вилучення сторінки з пошуку дозвольте сканування і додайте noindex.
Випадковий noindex у шаблоні
Після розробки або редизайну noindex іноді залишається на всіх сторінках, окремому типі сторінок або мовній версії. Перевірте типові URL: послуги, категорії, товари, статті, пагінацію, фільтри, сторінки міст.
Зайвий index, follow
Запис index, follow зазвичай не шкодить, але й не вирішує задачі. Якщо сторінка має індексуватися, достатньо не ставити обмежувальних директив.
Meta robots nofollow замість rel="nofollow"
Якщо потрібно позначити одне рекламне або партнерське посилання, не закривайте всі посилання на сторінці через meta robots nofollow. Використовуйте атрибут для конкретного посилання.
Noindex на сторінках із трафіком
Перед закриттям сторінки перевірте, чи не приносить вона покази, кліки або конверсії. Для сторінок із потенціалом іноді краще оновити контент, змінити структуру, доопрацювати перелінковку або об’єднати дублікати через canonical.
Noindex відсутній на тестовій копії сайту
Тестова копія сайту не повинна потрапляти в індекс. Ми часто бачимо цю помилку під час аналізу сайтів, які звертаються до SEO-Evolution після просідання трафіку: dev-домен, піддомен або технічна копія відкриті для сканування, сторінки мають стандартну поведінку index, follow і поступово з’являються в Google.
Це створює дублікати робочого сайту, плутає пошукові системи й може впливати на індексацію основних сторінок. Тестову версію краще закривати не тільки через noindex, а й через парольний доступ або обмеження за IP. Noindex підходить як додатковий рівень, але не як єдиний спосіб захисту технічної копії.
Noindex усього сайту в WordPress після запуску
Зворотна ситуація теж трапляється часто: сайт уже перенесли на робочий домен, але в WordPress залишилася увімкненою заборона індексації. У такому випадку сторінки можуть мати meta robots noindex, nofollow, хоча сайт уже має індексуватися й отримувати трафік з пошуку.
Перевірте це в адмінпанелі WordPress: Налаштування → Читання → Видимість для пошукових систем . Якщо стоїть галочка біля пункту Попросити пошукові системи не індексувати цей сайт , її потрібно зняти й натиснути Зберегти зміни . В англомовній адмінпанелі шлях виглядає так: Settings → Reading → Search Engine Visibility → Discourage search engines from indexing this site.
Після цього перевірте кілька важливих сторінок у Google Search Console через URL Inspection Tool. Якщо Google уже бачив noindex, йому потрібен час на повторне сканування й оновлення статусу сторінок.
Як перевірити noindex і meta robots у Google Search Console
Перевірку потрібно робити на кількох рівнях. Один перегляд HTML-коду не завжди показує всю картину, бо правило може приходити через HTTP-заголовок або змінюватися після рендерингу.
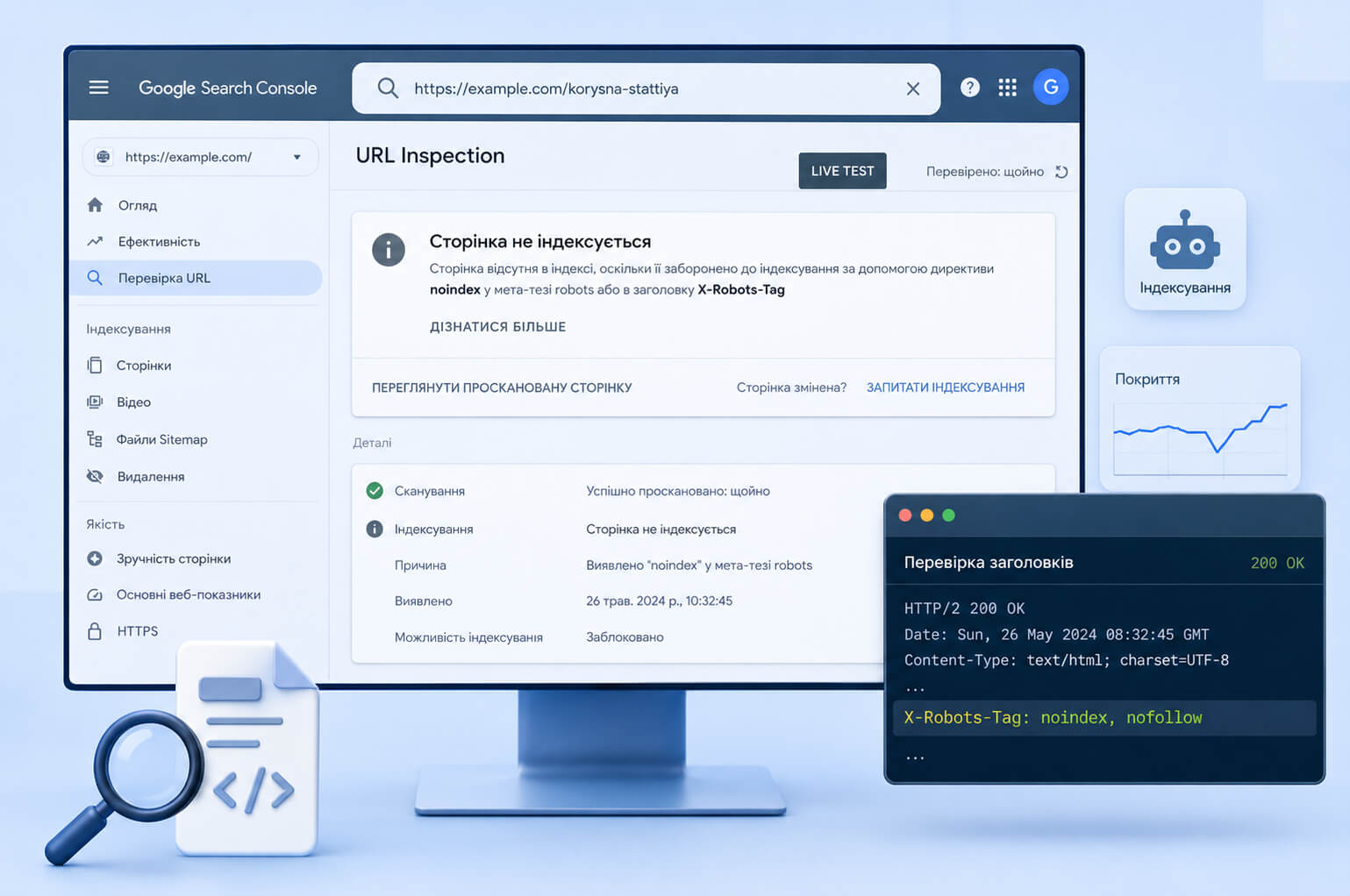
- Відкрийте сторінку в браузері, перегляньте вихідний код і знайдіть
meta name="robots". - Перевірте URL у Google Search Console через URL Inspection Tool.
- Запустіть live test, щоб побачити актуальну версію сторінки для Googlebot.
- Перегляньте Page Indexing report і знайдіть сторінки зі статусами, пов’язаними з noindex.
- Перевірте HTTP-заголовки, якщо підозрюєте X-Robots-Tag.
- Порівняйте meta robots, robots.txt, canonical і sitemap.
Для швидкої перевірки HTTP-заголовків можна використати команду:
curl -I https://example.com/file.pdfЯкщо у відповіді є X-Robots-Tag: noindex , індексацією керує серверний заголовок, а не HTML-код сторінки.
У Google Search Console проблема може відображатися як сторінка, де індексування заборонено тегом noindex. Якщо noindex уже прибрали, запросіть повторне сканування через URL Inspection Tool і дочекайтеся оновлення статусу. Для великої кількості URL оновіть sitemap і перевірте, чи не блокує сторінки robots.txt.
Висновок
Мета-тег robots потрібен для керування тим, як пошукові системи обробляють конкретну HTML-сторінку. Noindex відповідає за індексацію сторінки, nofollow — за посилання на сторінці. Це різні дії, тому їх потрібно налаштовувати окремо й не змішувати з атрибутами окремих посилань.
Robots.txt не замінює meta robots. Він обмежує сканування, але не є надійним способом прибрати HTML-сторінку з Google. Для заборони показу сторінки в пошуку використовуйте noindex, для PDF та інших не-HTML файлів — X-Robots-Tag, для видалених сторінок — 404, 410 або 301-редирект залежно від ситуації.
Перед змінами перевірте, які сторінки вже приносять трафік, де є дублікати, які URL потрібні користувачам, а які створюють технічний шум. Якщо noindex, canonical, robots.txt і sitemap налаштовані хаотично, SEO-просування сайту потрібно починати з технічного очищення індексації. Приклади комплексної роботи над сайтами можна переглянути в портфоліо SEO-Evolution .










