
Джон Мюллер з Google відповідає, чи існує відсотковий поріг, при якому Google ідентифікує будь-що як дубльований контент.
Джон Мюллер з Google нещодавно відповів на запитання, чи існує процентний поріг дублювання контенту, який Google використовує для виявлення та фільтрації дубльованого контенту.
Який відсоток відповідає дубльованому контенту?
Насправді розмова почалася на Facebook, коли Дуейн Форрестер ( @DuaneForrester ) запитав, чи хтось знає, чи публікує якась пошукова система відсоток перекриття контенту, при якому контент вважається дублюючим.
Білл Харцер ( bhartzer ) звернувся до Твіттера, щоб поставити запитання Джона Мюллера, і отримав майже негайну відповідь.
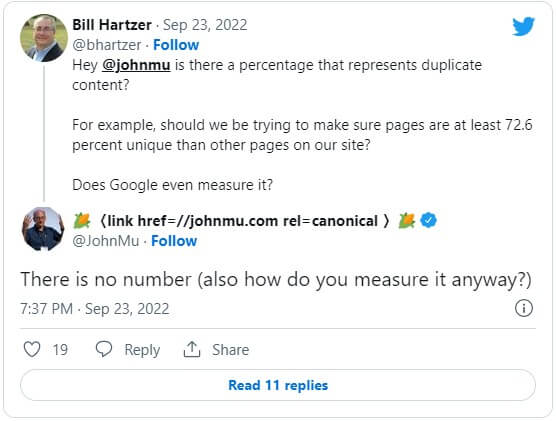
Білл написав у твіттері :
«Гей, @johnmu, чи є відсоток дубльованого контенту?
Наприклад, чи повинні ми прагнути, щоб сторінки були унікальними як мінімум на 72,6% порівняно з іншими сторінками на нашому сайті?
Google взагалі це вимірює?
Джон Мюллер з Google відповів:
Як Google виявляє дубльований контент?
Методологія Google для виявлення дубльованого контенту залишається напрочуд схожою протягом багатьох років.
Ще у 2013 році Метт Каттс ( @mattcutts ), інженер-програміст на той час у Google , опублікував офіційне відео Google, описує, як Google виявляє дубльований контент.
Він почав відео, заявивши, що більшість інтернет-контенту дублюється і що це нормально.
«Важливо розуміти, що якщо ви подивіться на контент в Інтернеті, приблизно 25% або 30% всього контенту в Інтернеті є контентом, що дублюється.
…Люди цитуватимуть абзац із блогу, а потім посилатимуться на блог тощо».
Далі він сказав, що оскільки так багато дубльованого контенту "невинно" і не містить намірів спаму, Google не каратиме цей контент.
За його словами, покарання веб-сторінок за дубльований контент негативно позначиться на результатах пошуку.
Що робить Google, коли знаходить повторюваний контент:
«…спробуйте згрупувати все це разом і ставитися до цього як одного фрагменту контенту».
Метт продовжив:
Це просто розглядається як щось, що нам потрібно відповідним чином згрупувати. І нам потрібно переконатись, що він ранжується правильно».
Він пояснив, що потім Google вибирає, яку сторінку показувати в результатах пошуку, і відфільтровує сторінки, щоб повторити взаємодію з користувачем.
Як Google обробляє дубльований контент - версія 2020
Перенесемося у 2020 рік, і Google опублікував епізод подкасту Search Off the Record, в якому та ж тема описана на диво схожою мовою.
Ось відповідний розділ цього подкасту з 06:44 хвилини до початку епізоду:
“Гері Іллієс: І тепер ми підійшли до наступного кроку, який насправді є канонізацією та виявленням дублікатів.
Мартін Сплітт: Хіба це не те саме, що й виявлення дублікатів та канонізація?
Гері Іллієс: [00:06:56] Ну, це не так, так? Тому що спочатку ви повинні виявити дублікати, по суті, згрупувати їх разом, кажучи, що всі ці сторінки є дублікатами один одного,
а потім потрібно знайти сторінку-лідер для всіх з них.
…І це канонізація.
Отже, у вас є дублювання, яке є цілим терміном, але всередині нього у вас є побудова кластера, як створення дублюючого кластера, і канонізація.
Потім Гері пояснює у технічних термінах, як саме вони це роблять. По суті Google насправді не дивиться на відсотки точно, а швидше порівнює контрольні суми.
Можна сміливо сказати, що контрольна сума є уявлення вмісту як послідовності цифр чи букв. Таким чином, якщо вміст дублюється, послідовність чисел контрольної суми буде аналогічною.
Ось як Гері пояснив це:
«Отже, для виявлення обману ми робимо таке: ми намагаємося виявити дублікати.
І те, як ми робимо це, можливо, те саме, що роблять більшість людей в інші пошукові системи, тобто, переважно, скорочує вміст до хешу або контрольної суми, а потім порівнює контрольні суми».
Гері сказав, що Google робить це так, тому що це простіше (і, очевидно, точніше).
Google виявляє дубльований контент за допомогою контрольних сум
Таким чином, коли мова йде про контент, що дублюється, це, ймовірно, не питання процентного порога, де є число, при якому контент вважається дубльованим.
Натомість дубльований контент виявляється з поданням контенту у вигляді контрольної суми, а потім ці контрольні суми порівнюються.
Додатковий висновок у тому, що, очевидно, існує різницю між дублюванням частини контенту і дублюванням всього контенту.








